728x90
반응형
Ch9. Dictionary
-리스트는 순서를 유지하는 값들의 컬렉션인 것과 달리 딕셔너리에는 순서가 없고 모든 원소들은 키 값을 가지고 있다.
딕셔너리는 값을 찾기 위해 숫자 대신에 키 값을 이용한다는 것에서 리스트와 큰 차이를 보인다. (나머지는 비슷!)
- 딕셔너리의 응용
get 메소드

두 개의 반복 변수
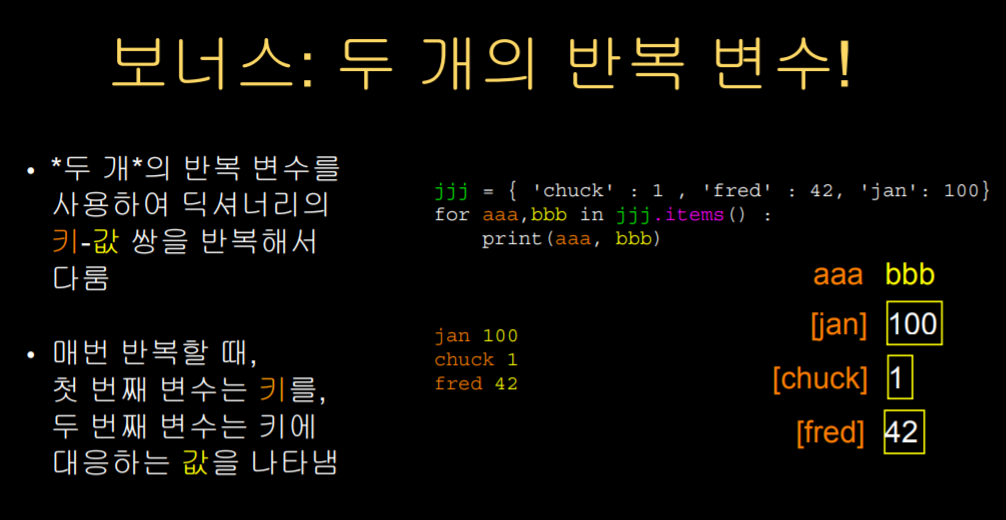
ex)

#사용자에게 파일 이름 입력받기
name = input("Enter file: ")
#파일 이름이 1보다 작으면 지정해 둔 이름으로 출력될 수 있게 하기
# -> 즉 엔터를 입력하면 "mbox-short.txt"로 바로 입력됨!!!
if len(name) < 1:
name = "mbox-short.txt"
# try except문을 이용해서 잘못된 형식의 파일 이름이 입력 되었을 경우 예외처리 하기
try:
handle = open(name)
except:
print("잘못된 형식의 파일 이름입니다.")
quit()
#개수를 세는 counts는 빈 딕셔너리 생성, lst는 빈 리스트 생성
counts = dict()
lst = list()
# txt파일들 중 from으로 시작한 문장 필터링 후 인덱스 번호 1번째 위치에 있는 원소들만 걸러내서 append 메소드를 사용해 빈 리스트에 추가하기!
for line in handle:
if not line.startswith('From '): #'From'으로 시작하는 문장만 추출하기
continue
wds = line.rstrip().split() #출력한 문장들의 오른쪽 공백을 제거하고 단어별로 분리하기
value = wds[1] #이메일 주소에 해당하는 인덱스 번호 1번째에 위치하는 원소들만 value라는 변수에 저장.
lst.append(value) #그것들만 빈 리스트에 추가하기
for word in lst:
counts[word] = counts.get(word,0) + 1 #리스트에 있는 요소들이 총 몇 번씩 있는지 세기
print(counts) #딕셔너리 형태로 {yewon:1}이런식으로 출력됨!
# 제일 많이 나온 단어와 그 횟수를 출력하기 위해 다음과 같이 변수 지정.
bigcount = None
bigword = None
for word,count in counts.items():
if bigcount is None or count > bigcount:
bigword = word
bigcount = count
print(bigword, bigcount)
* 오래 걸렸지만 온전히 내 힘으로 해낸 것이라 무지무지 뿌듯하다!!ㅎㅎㅎ
+ 코드블럭을 사용할 수 있다는 걸 이번에 처음 알아서 해봤는데, 캡쳐해서 하는 것 보다 훨씬 편하고 좋다...ㅎㅎ..... 이젠 맨날맨날 이거 써야지.
Ch10. Tuple
-리스트와 튜플은 매우 비슷하다. 눈에 띄는 차이는 대괄호 대신 소괄호를 사용했다는 것 정도인데 리스트처럼 순서가 있어서 인덱스로도 접근이 가능하고 최대값도 찾을 수 있다. But!! 튜플은 리스트와 달리 값의 변경이 불가능하다.
-> 이러한 속성들로 인해 용량을 덜 차지하고 빠르게 처리할 수 있다. 또 여러 값에 대해 비교가 가능하다!
ex)
name = input("Enter file: ")
if len(name) < 1:
name = "mbox-short.txt"
try:
handle = open(name)
except:
print("Invalid")
quit()
# 앞의 예제와 똑같은 방식으로!
lst = list()
di = dict()
for line in handle:
if not line.startswith('From '):
continue
wds = line.rstrip().split()
# 찾아서 나눈 후 인덱스 5번째에 위치하는 시간을 출력한다.
value = wds[5]
# 시간중에서도 hour에 해당하는 부분만 필터링하기 위해서 ':' 구분자를 지정해서 출력한다.
time = value.rstrip().split(':')
# 그 중 hour의 숫자만 카운트할 것이기 때문에 인덱스 0번째에 위치하는 '시'를 hrs에 넣어준다.
hrs = time[0]
# 아까 만들어둔 빈 리스트 lst에 append 메소드를 사용하여 추가!
lst.append(hrs)
# 리스트 lst 안에 있는 요소들의 개수 카운트하기
for w in lst:
di[w] = di.get(w,0) + 1
# 튜플로 나타내기 위한 빈 리스트 생성
tmp = list()
# List Comprehension 으로 동적인 리스트 생성
tmp = sorted([(v,k) for v,k in di.items()])
# 반복문을 사용하여 왼쪽에는 시간, 오른쪽에는 개수를 출력
for v,k in tmp:
print(v,k)
* 코드 마지막 줄 tmp[:3]등 슬라이싱을 활용해 지정 범위만큼만 출력할 수도 있다.
* 또 v,k의 위치를 바꿔서 키를 기준으로 출력하는 것이 아니라 값을 기준으로 출력할 수도 있다.
파이썬 문법 공부 끄읕-!
728x90
반응형
'Programming Language > Python' 카테고리의 다른 글
| Python - 최대 재귀 한도 깊이로 인한 Runtime Error 해결 방법 (0) | 2022.06.22 |
|---|---|
| Python - 데크(deque)의 개념 (0) | 2022.05.27 |
| CodeUp 기초 100제 정리 (0) | 2021.07.13 |
| Python - 문법 공부 정리(5~8) (0) | 2021.07.02 |
| Python - 문법 공부 정리(1~4) (0) | 2021.07.01 |


